|
I am a fourth-year Ph.D. student in the Department of Automation at Tsinghua University, advised by
Prof. Jianjiang Feng and
Prof. Jiwen Lu.
In 2022, I obtained my B.Eng. in the XUTELI School, Beijing Institute of Technology.
Email / CV / Google Scholar / Github |

|
|
|
|
|

|
Wenxuan Guo*, Ziyuan Li*, Meng Zhang, Yichen Liu, Yimeng Dong, Chuxi Xu, Yunfei Wei, Ze Chen, Erjin Zhou, Jianjiang Feng arXiv preprint, 2026 [arXiv] [Code] [Project Page] We propose GesVLA, a gesture-aware VLA that embeds hand cues to disambiguate targets in cluttered manipulation scenes. It improves human-robot interaction efficiency and real-robot performance on multiple practical tasks. |

|
Wenxuan Guo, Xiuwei Xu, Yichen Liu, Xiangyu Li, Hang Yin, Huangxing Chen, Wenzhao Zheng, Jianjiang Feng, Jie Zhou, Jiwen Lu Computer Vision and Pattern Recognition (CVPR), 2026 [arXiv] [Code] [Project Page] We propose AwareVLN, a framework with sparse self-aware reasoning at key navigation nodes via a unified reason-act VLM. An automatic data engine scales structured supervision without manual annotation. It outperforms prior methods on R2R-CE/RxR-CE and deploys on a real quadruped. |
|
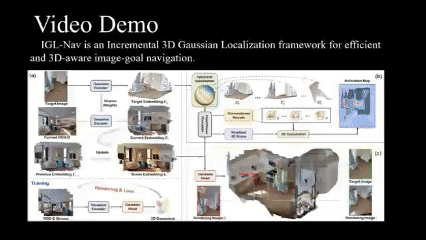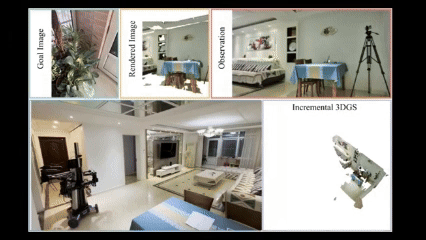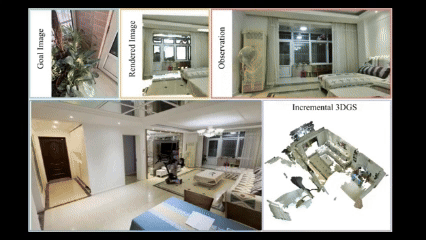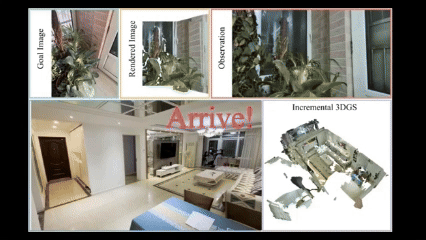
Wenxuan Guo*, Xiuwei Xu*, Hang Yin, Ziwei Wang, Jianjiang Feng, Jie Zhou, Jiwen Lu International Conference on Computer Vision (ICCV), 2025 [arXiv] [Code] [Project Page] We propose IGL-Nav, an incremental 3D Gaussian localization framework for image-goal navigation. It supports challenging scenarios where the camera for goal capturing and the agent's camera have very different intrinsics and poses, e.g., a cellphone and a RGB-D camera. |
|
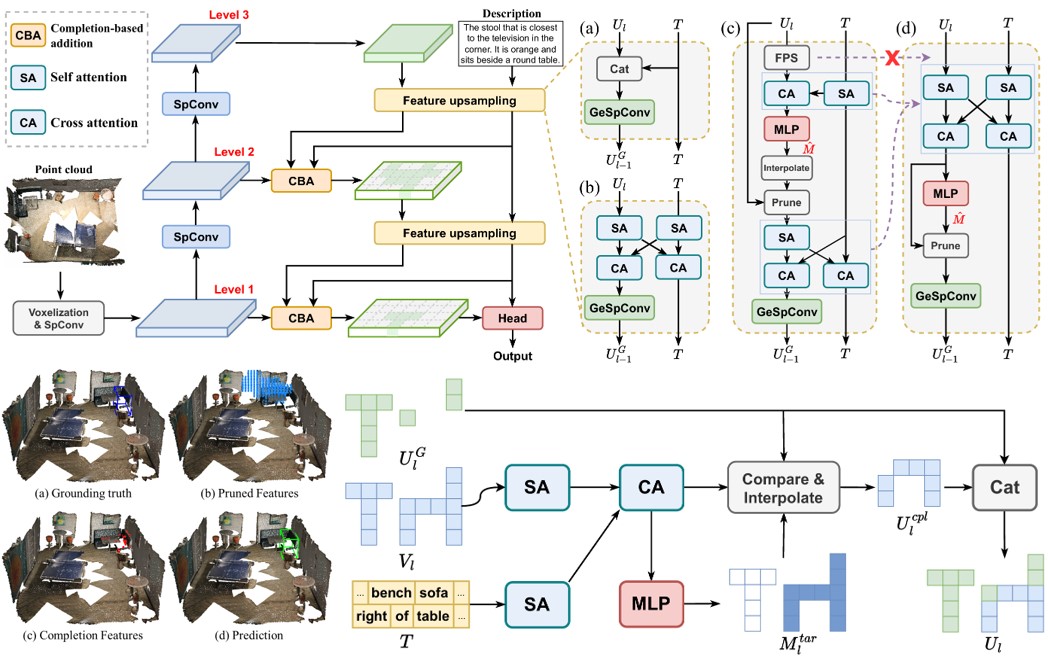
Wenxuan Guo*, Xiuwei Xu*, Ziwei Wang, Jianjiang Feng, Jie Zhou, Jiwen Lu Computer Vision and Pattern Recognition (CVPR), 2025 (Rating: 555) [arXiv] [Code] [中文解读] We propose TSP3D, an efficient multi-level convolution architecture for 3D visual grounding. TSP3D achieves superior performance compared to previous approaches in both accuracy and inference speed. |
|
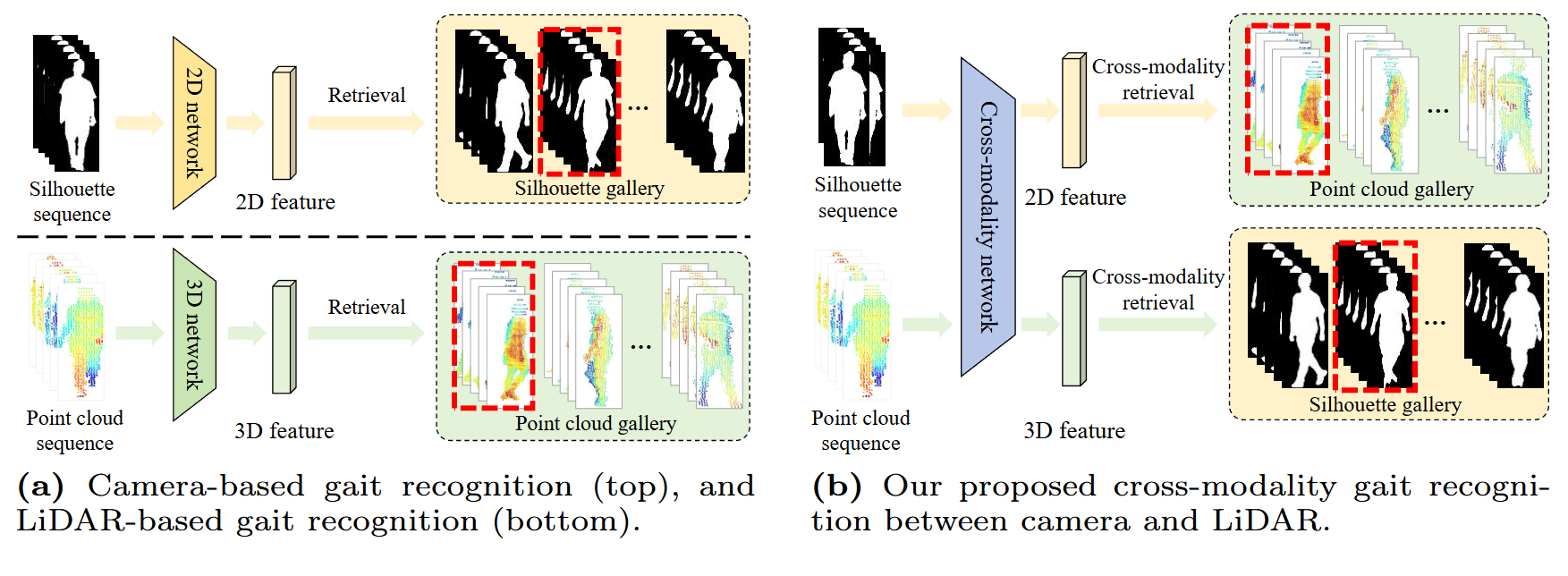
Wenxuan Guo*, Yingping Liang*, Zhiyu Pan, Ziheng Xi, Jianjiang Feng, Jie Zhou European Conference on Computer Vision (ECCV), 2024 [arXiv] [Code] We propose CL-Gait, the first cross-modality gait recognition framework between camera and LiDAR. We propose a contrastive pre-training method to align the feature spaces of the two modalities, along with a large-scale data generation strategy. |
|
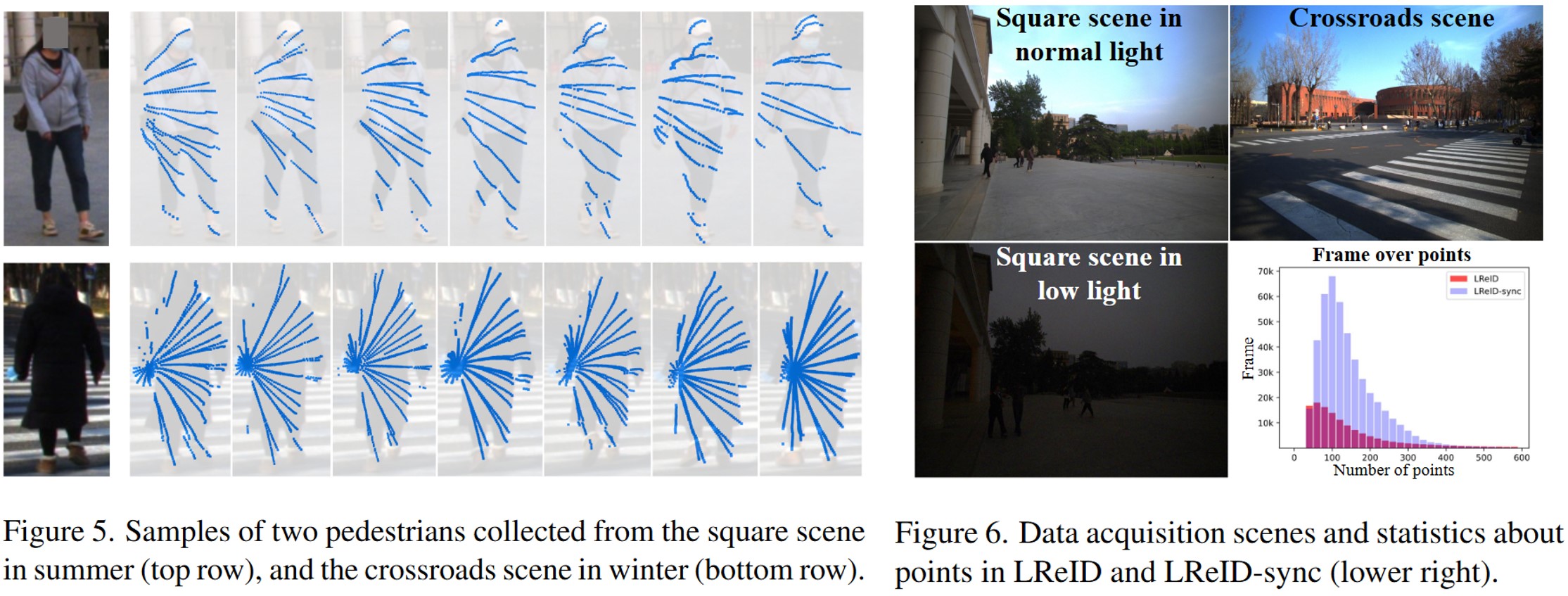
Wenxuan Guo, Zhiyu Pan, Yingping Liang, Ziheng Xi, Zhicheng Zhong, Jianjiang Feng, Jie Zhou Computer Vision and Pattern Recognition (CVPR), 2024 [arXiv] [Code] [中文解读] We propose ReID3D, a LiDAR-based ReID framework that utilizes a pre-training strategy to retrieve features of 3D body shape. Additionally, we build LReID — the first LiDAR-based person ReID dataset, which is collected in several outdoor scenes with natural variations. |
|
|
|
GesVLA |
Gesture-Aware Robot ManipulationGesVLA introduces gesture as a parallel instruction modality to disambiguate targets in cluttered scenes and improve human-robot interaction efficiency. Hand cues are encoded in a dual-VLM for joint intent reasoning and action generation, with semi-synthetic data and two-stage training for strong real-robot performance on block, jelly, and produce selection. |
|
AwareVLN |
Self-aware Vision-Language NavigationIn AwareVLN, we equip VLN with sparse self-aware reasoning at key nodes via a unified reason–act VLM, together with an automatic data engine for scalable structured supervision. AwareVLN achieves strong results on R2R-CE and RxR-CE with monocular RGB and deploys on a real quadruped. |
|
IGL-Nav |
3D Representation for Visual NavigationWe propose incremental 3D Gaussian localization for free-view image-goal navigation in IGL-Nav. We support a challenging application scenario where the camera for goal capturing and the agent's camera have very different intrinsics and poses, e.g., a cellphone and a RGB-D camera. |
|
|